Первые 5 шагов дебага в PostgreSQL, которые решают 90% проблем


— Алле, добрый день, мне дали ваш номер и сказали, что вы можете нам помочь?
Я: А какая у вас проблема?
— Ну, у нас PostgreSQL зависает, из-за этого периодически не работает система. Можете нам помочь?
Я: Конечно, я решу ваши проблемы, но это будет стоить дорого.
Вот так примерно сейчас я веду разговоры, когда ко мне приходят с подобными проблемами. Раньше я говорил: давайте посмотрим, что там у вас. Может, там база размером 10ТБ? DBA отшлифовал все запросы и теперь не знает, куда дальше копать? Может, они столкнулись с багом PostgreSQL? Или, может быть, какая-нибудь неведомая advanced проблема?
Но в 90% случаев проблемы очень простые и на поверхности. С помощью пяти простых шагов, которым меня когда-то научил мой "учитель", мне зачастую удается решать основные траблы, связанные с PostgreSQL.
Шаг первый.
Это базовые настройки PostgreSQL. Тут, как правило, все смотрят на конфиг PostgreSQL postgresql.conf и просто удивляются от количества крутилок там. Но я подскажу, как можно настроить базу для решения 90% проблем.
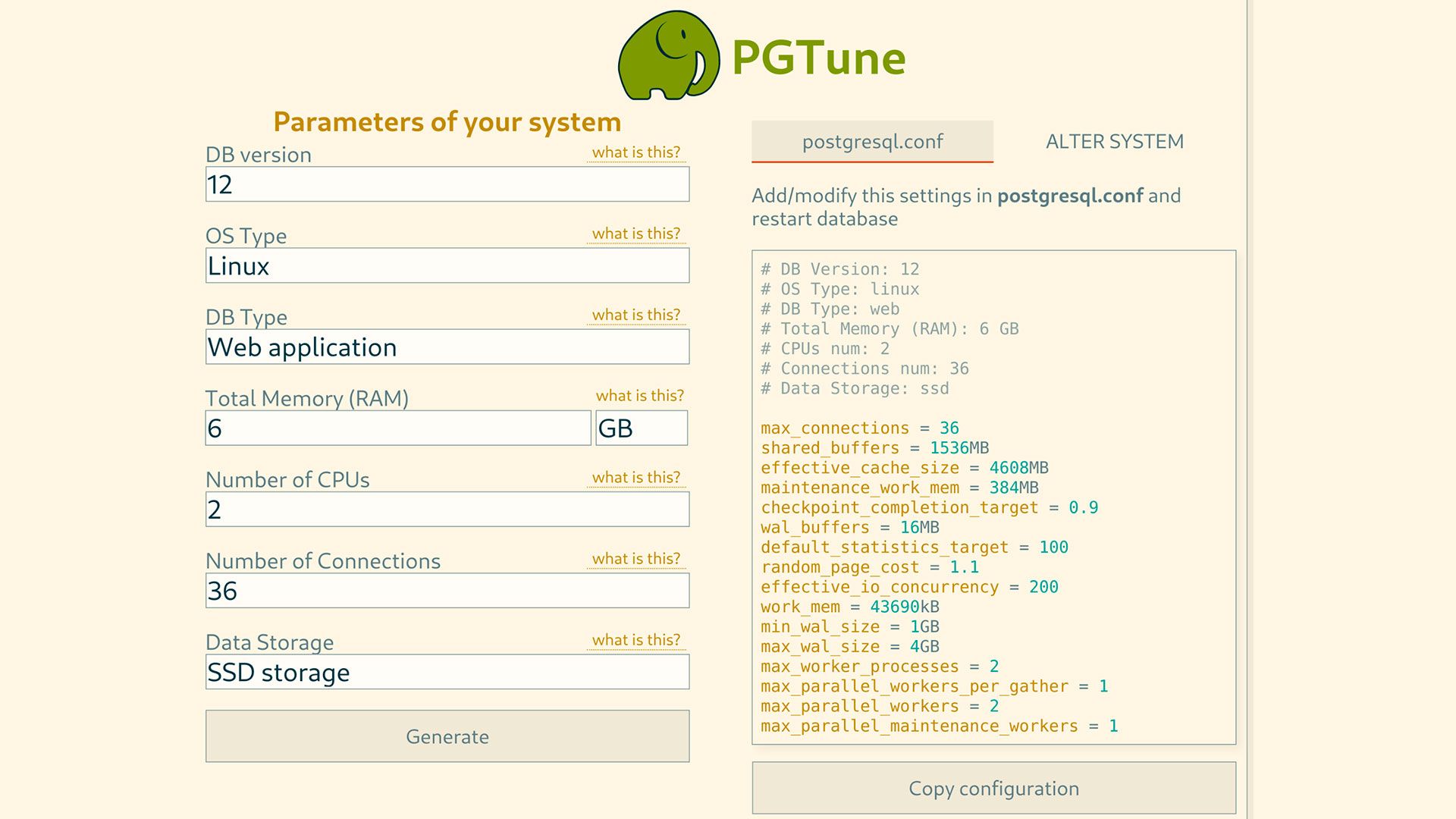
В первую очередь, нужно узнать, сколько ресурсов доступно базе. Бывают случаи, когда рядом с базой сажают совсем ненужное, типа бинарика или jar-ика от разработчика, или еще что-то. Тут главное понять, сколько памяти осталось БД. Если база стоит на отдельной виртуалке или серваке, то это успех. Можно брать в расчет всю память и CPU сервака или виртуалки.
Второе, нужно 5 раз, а, возможно, и того больше, спросить у разрабов, сколько соединений в базу они у себя накрутили в приложении. А потом еще и проверить самому. Часто бывает, что разработчики настраивают по дефолту и не знают или ошибаются в размере конекшн пула. Как только эти данные получены, начинается магия. Заходим на сайт https://pgtune.leopard.in.ua/#/ там вбиваем данные о нашей базе и жмякаем generate и вуаля — сайтик дает настройки, которые нужно применить у себя. Судя по тому, насколько неправильно в основном настроена была память базы, мне показалось, что сайт был долгое время засекречен рептилоидами от общих масс. И, да, обязательно подключаем ‘pg_stat_statements'.
- # postgresql.conf
shared_preload_libraries = 'pg_stat_statements'
После всех этих шагов нужно перезапустить БД.
Ну все, полработы сделано, и тут смело можно просить 50% оплаты.
Шаг второй.
В случае с LINUX: TOP, HTOP, IOSTAT, iftop. Тут нужно понимать, что если проблема постоянная, то отловить, во что упирается база, с помощью инструментов выше будет несложно, а вот если проблемы фантомные, то нужно уже собирать показатели в какой-то мониторинг.
Прогоняем TOP/HTOP, чтобы посмотреть, не уперлись ли мы CPU и какой LOAD AVERAGE. Подсказка — если LA больше, чем количество ядер, то, скорее всего, мы во что-то уперлись. Прогоняем iostat -x 1, и смотрим на графу %util. Эта графа обозначает процент времени CPU, в течение которого запросы ввода-вывода были выданы устройству. Если она близка к 100%, то значит процент все время отдал на I/O диска (блочного устройства) и, скорее всего, вы уперлись в диски.
Кстати, часто люди не знают, как отобразить этот показатель в prometheus. Так вот, у node_exporter есть такой показатель node_disk_io_time_seconds_total. Его дериватив (rate), умноженный на 100, будет как раз %util. Прогоняем iftop и смотрим, как там наша сеть, возможно, мы уперлись в нее.
Этот шаг должен нам дать понимание, является ли узким местом сервер, или ВМ, на которой размещена база. И, возможно, проблема решится переносом базы на SSD или добавлением памяти или CPU. Если есть возможность, залейтесь железом. Но не забудьте снова пройти 1-ый шаг, если параметры сервера изменились. И если системе стало лучше, и она не зависает, берите оставшиеся 50% и закрывайте кейс. Если не помогло, нет ресурсов или уже все залито железом, то переходим к следующему шагу
В случае с WINDOWS это все, конечно, можно посмотреть в "Performance Monitor" или "Task Manager" но лучше конечно переехать на Linux.
Шаг третий.
Pg_stat_activity. Если проблема фантомная, и она происходит в рандомное время, то переходи к 4-му шагу. Но если проблема постоянная, или мы знаем время, когда возникают проблемы, то заходим в нашу базу и запускаем следующую команду
- SELECT query, state, count(*) FROM pg_stat_activity WHERE state != 'idle' GROUP BY query, state;
И что смотреть? Всё. Как правило, тут я нахожу почти все проблемы. База зависает, a pg_stat_activity тебе показал из-за чего. Берите все запросы, где state = active. В основном, это SELECT-ы, берем их и смотрим через EXPLAIN ANALYZE все ли "ОК" с индексами. Тут, как правило, даже самые опытные разработчики допускают ошибки в погоне за фичами. Довольно редко это UPDATE, INSERT или DELETE, как правило, проблема в том, что таблицы перегружены индексами. Тут нужно смотреть статистику индексов, как это делать, посмотреть можно тут https://wiki.postgresql.org/wiki/Index_Maintenance.
Кстати, PgAdmin отлично показывает статистику по таблице, там же есть статистика по индексам.
После этого шага, как правило, отпадает большинство проблем. И я забираю бабки и ухожу в закат. Для таких случаев даже байк можно купить, чтобы уход был эффектнее. Ну, или как вариант косуху!
Но иногда бывает так, что уходить еще рано, нужно еще собрать статистику, чтобы причесать систему.
Шаг четвертый.
Pg_stat_statements. В первом шаге мы подключили библиотеку pg_stat_statements. Чтобы ее активировать, заходим в psql, ну или подключаемся к базе через какую-нибудь GUI и прогоняем
- CREATE EXTENSION pg_stat_statements.
Вуаля, у тебя появилась таблица pg_stat_statements. Что она дает и о ее возможностях, можно прочитать тут https://postgrespro.ru/docs/postgresql/14/pgstatstatements. Тут я опишу одну примитивную операцию, которая в принципе решает основные проблемы. И для этого нужно прогнать
- SELECT query, calls, total_exec_time FROM pg_stat_statements ORDER BY total_exec_time DESC LIMIT 20
Что это нам дает? А дает это нам статистику запросов, которые съедают больше всего времени. Не всегда в топе тяжелый запрос, чаще это запрос, который вызывается очень часто, но при этом время обработки запроса не высокое. И тут я приведу вам сейчас пример.
Представьте, есть запрос, чье время обработки 15 мс, и вызывается он 1000 раз в минуту.
Есть запрос на 10 сек или 10 000 мс и вызывается он раз в час. Так вот, если оптимизировать первый запрос на 5 мс, то мы за час мы выиграем 300 000 мс.
Так что смело идем сверху вниз и тюним запросы. После тюна обязательно нужно сбросить статистику.
- SELECT pg_stat_statements_reset();
Шаг пятый.
log_min_duration_statement: это настройка которая позволяет логировать все запросы, превышающие заданный порог. И самое прекрасное, что его можно изменять на лету.
- SET log_min_duration_statement TO 200;
SELECT pg_reload_conf();
Я обычно выставляю 200 и потом уже смотрю логи, если логов мало, выставляю ниже и смотрю, что там прилетает. Глазами можно увидеть, как часто и какого рода прилетают тяжелые запросы. Ну, естественно, тюним их, и базе становится легче дышать.
Заключение
Как правило, этих 5 шагов мне достаточно, чтобы привести в порядок средненький проект, были кейсы даже, когда этого хватало для систем с 1-2 тыс rps. Но, конечно, бывают отдельные случаи, которые заставляют попотеть так, что не пожелаешь и врагу, и пару таких адовых кейсов я хорошо помню. Но про них в следующий раз.
В заключении МЕМЧИК.
